Surviving SAN failure – Revisited (vSphere)
Some time ago I posted Surviving total SAN failure which I had tested on ESX 3.5 at the time. A recent commenter had trouble getting this to work on a vSphere 4.0 environment. So I set out to test this once more on my trusty vSphere 4.1 environment.
The General Idea
VMware is constantly thinking about how to cope with server failure, and they are doing a pretty decend job. But what about SAN failure? Surely, if you have a top-notch SAN or NAS the chances of it failing are very very slim. But what if you have a less reliable SAN or NAS? In this blog entry I’ll show a way you can protect your most valuable VMs by mirroring their virtual disks across two SANs (or even across a NAS and a SAN or two NASses).
To The Lab!
Storage setup
So here we go again with some lab time. I wanted to test on two SANs, but I used a shortcut this time. I created a separate RAID0 disk set on my shared storage, and I carved two LUNs out of it. Then I mapped those LUNs to my vSphere 4.1 nodes. A rescan of the storage, formatted the LUNs (named FAIL-LUN0 and FAIL-LUN1) and all was set at the storage side of things. I can simulate LUN failure by simply telling the storage box to remove any of the LUN’s mapping to the vSphere nodes.
Virtual machine setup
As a virtual machine I used a Windows 2003R2 x64 server image, which I deployed from a template onto FAIL-LUN0. I called the VM “Kenny”, hopefully we’re not going to be able to actually Kill Kenny this time 😉
After it had gone through sysprep, I logged into the VM and changed its disk type to “dynamic”. This is a requirement for a software mirror that we will be building.
When the VM was booted again, I added a second virtual disk which I put on FAIL-LUN1, the same in size as the initial virtual disk (in my case 12[GB]). Initialized this disk to be dynamic as well, then added a mirror to the bootdisk (right click on the bootdisk from Disk Management, then select “add mirror”). The mirror started to sync:

Syncing a software mirror of the boot device in Windows 2003 server
Config file setup
After the VM was completely in sync, I shut down the VM, removed it from vCenter (using “remove from inventory”) just to be sure, then edited the *.vmx file to include the following line:
scsi0.returnBusyOnNoConnectStatus = “FALSE”
This line is a requirement for our setup, because by default vSphere will return “BUSY” to a VM whenever the LUN is unreachable. This will effectively freeze the VM, and never break the software mirrorset. With this line inserted, vSphere will return an “ERROR” when a LUN fails instead of “BUSY”, effectively breaking the software mirror and not freezing the VM (but hopefully continue to run).
Finally I added the VM back to vCenter (by browsing for it, then right clicking on the Kenny.vmx file and choose “add to inventory”).
When the VM reboots, the software mirroring of the two disks is also added in the boot.ini file, enabling you to boot from the second virtual disk in case the primary is damaged/out of sync:
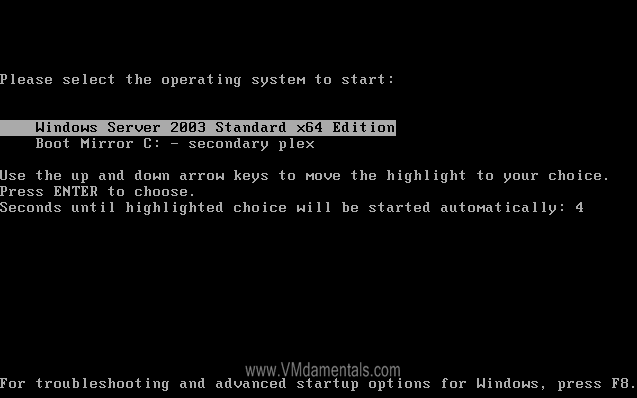
Dual boot option screen after adding the software mirror
Now we are all set. The VM runs from a software mirror, with both disks on a separate LUN. Up next, my favorite part:
Time to Break Stuff
My favorite part: De-mo-li-tion! Now that the VM is up and running, and hopefully protected by the software mirror across two LUNs, the next step is to login to the shared storage device, and UNMAP the FAIL-LUN1 from the hosts:

View on my (t)rusty shared storage device while unmapping FAIL-LUN1 from the vSphere nodes
Just about one second after unmapping the LUN from the vSphere node running my Kenny VM, I have a result: The software mirror breaks, and the VM resumes to function:

A LUN is lost, the mirror breaks: The VM resumes on a ‘single leg’
Success! The mirror breaks, the VM goes on. I just lost a SAN and my VM keeps running! This test was the “easiest”: I broke the LUN where only the second virtual disk was housed. So now we go on to break some more: FAIL-LUN0 (where the VM config is!)
First I needed to resync both disks. I mapped FAIL-LUN1 back to the hosts, and forced the software mirror to resync:
Reactivating the software mirror to handle a new failure in the future
After the sync was complete, it was time to unmap FAIL-LUN0. This is a bit more exciting, because all the VMs stuff is on there.
Failing the LUN where the VM config is located
When I unmapped FAIL-LUN0, it initially worked just like in the previous case: The mirror broke, the VM resumed. All is well you might say. But something did not feel right: I just unmapped one of the disks, but also the entire VM’s config. So I setup the test again, and failed FAIL-LUN0 again. This time the VM frooze. The mirror did not break, the VM just frooze forever! “Oh my god they killed Kenny!”… When I mapped the LUN back again, the VM just unfrooze and went about its business. The mirror did not break at all!
So what causes this behavior? First I believed the problem lies within in the vswp file, the file used by VMware to swap memory if all else fails. As FAIL-LUN0 was unmapped from the vSphere servers, the VM might continue to run from its second disk if no files are accessed on the now failed FAIL-LUN0 … You could potentially get around this problem by setting a memory reservation on the VM, effectively reducing the vswp file size to zero.
Unfortunately, that did not help. Even with the vswp file at size zero, the VM freezes every once in a while, and refuses to break its mirror. Up till now, when failing the FAIL-LUN0 and the VM fails, I can always restore the LUN and the VM continues. Failing the LUN again right after the first fail, will trigger the software mirror to break.
On to the next and most evil: more undocumented features! I stumbled upon this vmx option (from the great list of undocumented vmx parameters at virtuallyghetto.com):
scsi0.returnNoConnectDuringAPD = "TRUE"
The APD refers to the term “All Paths Dead”. So what does it do? Not certain, that is why it is undocumented (duh!). I assume this option will tell the scsi0 device to return a “NO CONNECT” if all paths fail. And loosing an entire SAN will definitely kill all paths, so I might have something there. My first guess was to set this variable to “TRUE”: In this case it will break whatever can be broken, just what we need since the VM is perfectly capable to cope with a LUN failure! Hopefully this will force the software mirror to break, without breaking the VM and “killing Kenny” again 🙂
After syncing both “plexes” within the VM (AGAIN, boy that takes time!), I was ready to put it to the test. So I added scsi0.returnNoConnectDuringAPD = “TRUE” to the vmx config file. And it seems to have done the trick; the first time I failed the primary LUN the software mirror nicely broke and the VM resumed its business right away. After some more tests, I managed to break the mirror time and time again; I am pretty sure this solves the problem about a VM freezing if the LUN where its config resides fails.
Hints and Tips
Some useful hints and tips to get you going:
Overhead
So how to implement this practically? First off, I would not configure this for all of your VMs. It is important to separate vital VMs from the important ones – and decide accordingly. Remember, if your SAN fails you have to find some way to restore the software mirror – within ALL VMs you had protected this way!
Make sure no vswp file exists
Because the vswp file might need to be written to, you’d want to avoid vSphere would try to write to a failed LUN (possibly freezing the VM in the process). Putting a memory reservation on the VM the samesize as the VM’s configured amount of memory will effectively create a vswp file of zero bytes (and this certifies it will never be written to). Another option would be to move all vswp files to a third location (like local storage). Take care; this will impact VMotion performance and has some other issues (like possibly filling up the local storage if too many VMs run on a single vSphere server).
Create a Standby VM
As described above, there have been times where the VM refused to break their mirror. I’m still looking into that, never seen it under ESX 3.5. But how to recover from a situation like that? Well, there is a simple solution: If a VM freezes instead of breaking its mirror, you should have created a “standby” VM. This standby VM is configured the same as the primary VM, but instead of mounting both disks, you create the VM on the second LUN/SAN (FAIL-LUN1 in my case), and you mount only the second disk.
If a VM refuses to break the mirror and freezes, all you have to do is shutdown the frozen VM, and start the standby VM! This standby VM will use the second “plex” as its main bootdrive, and it should boot the VM normally. This way, you can keep downtime to a minimum, even when one of your SANs fail completely.
The Weakest Link
Do not forget that the disk speed the VM will be able to perform, will be limited to the slowest of both LUNs. If your basic bootdisk resides on a fast LUN, and you create a mirror on a much slower LUN, the VMs disk speed will be reduced to match the speed of that slower LUN (and possibly even less than that).
I feel another lab session coming on! 😉


 LinkedIn
LinkedIn Twitter
Twitter
Your post rocks! It is a very nice insight in Vmware behavior. Some time ago I wrote a post on an error I got on a VM which had lost its iSCSI storage (http://www.happysysadm.com/2010/09/vmware-guests-and-iscsisan-storage.html) and I found a registry key in charge of managing Windows bahavior in case of SAN failure: HKEY_LOCAL_MACHINE/System/CurrentControlSet/Services/Disk/TimeOutValue. Had you made any change to the value of this registry key beforehand?
Thanks
Carlo
Hi Carlo,
I did not configure anything special within the VM (except the software mirror of course). Basically I do not want to limit anything to VM-specific changes, which should make it work for Linux/Solaris VMs as well.
Funny that you point to this registry entry: VMware Tools boosts this value to 60 seconds (instead of the default of 10). This would mean the VM freezes for up to 60 seconds before things go wrong (bluescreen?). Anyways, for the way I work in this post even 10 seconds would be way too long. The “failover” speed in my solution is about one second from the moment the VM performs (or tries to perform) any disk I/O.
Hi Erik,
I know this enrtry is from awhile ago, but I thought I’d ask anyway.
I have a few ESXi 3.5 servers that use the scsi0.returnBusyOnNoConnectStatus = “FALSE” flag and the VM’s have no issue’s if we drop one of our iscsi sans offline. They continue to run and do not lock up.
I’ve tried the same settings on ESXi 4.0, 4.1, 4.1u1, ESX 4.1u1 and I cannot get it to work. Everytime we disconnect the from the san the VM and VSphere freeze…even just trying to go to “Edit Settings” we get a timeout error “Call “PropertyCollector.RetrieveContents” for object “ha-property-collector” on ESX “Server IP” failed”. Plug the san back in and the VM/Vsphere come back to life instantly. It doesn’t matter if the VM has a drive mirrored with another san or not. We have the Guest OS installed on a local disk so that it won’t be affected by removing the san (I just stop the Openfiler iscsi service).
Any ideas? I went through this entry and tried the other flag as well, even allocating a reservation of memory but had no success.
Hi Luke,
I’m sorry but I haven’t tested these settings lately on the newest releases of vSphere. There are not that many people seriously using this. It might be interesting to test this once again, if time permits. But there is the real problem… Time…… 🙁