Posts Tagged ‘WOPS’
Backwards VDI math: Putting numbers to the 1000 user RA
EMC and VMware have published a joined Reference Architecture where an EMC VNX5300 using a minimum configuration of disks squeezes out the required IOPS for a thousand VDI users. That is awesome stuff, but how to go about using and remodeling this RA for your own needs? In this blog post I’ll try to put some numbers to it, both validating and enabling you to resize for your needs.
A very cool use case: VMware View and 1000 vDesktops running off an EMC VNX5300
This is a very VERY cool one. You can find the Reference Architecture Read the rest of this entry »
vscsiStats in 3D part 2: VMs fighting over IOPS
vscsiStats is definitely a cool tool. Now that the 2D barrier was broken in vscsiStats into the third dimension: Surface charts! it is time to move on to the next level: Multiple VMs fighting for IOPS!
Update: Build your own 3D graphs! Check out vscsiStats 3D surface graph part 3: Build your own!
I figured the vscsiStats would be most interesting in a use case where two VMs are battling for IOPS from the same RAID set. A single VM would have to force I/O on a RAID set. Wouldn’t it be cool to start a second VM on the same RAID set later on and to see what happens in the 3D world? In this blogpost I’m going to do just that!
TO THE LAB!
The setup is simple: Take a LUN on a RAID5 array of (4+1) SATA72K spindles, take two (Windows 2003 server) VMs which have a datadisk on this LUN. Now install iometer on both VMs. These two instances of iometer will be used to make both VMs fight for IOPS.
The iometer load is varied between measurements, but globally it emulates a server load (random 4K reads, random 4K writes, some sequential 64K reads).
First only a single VM runs the iometer load. At 1/3rd of the sample-run, the second VM is started to produce the same IO pattern. At 2/3rd, the first VM stops its IO pattern load. This results in the following graph:

Throughput part 4: A day at the races (Hotspotting case)
The fourth part of this triptych ( 😉 ) is a customer case of hotspotting on storage. The graphs speak for themselves! Some storage design decisions they made caused them a lot of trouble…
Birth of the storage design
The customer in question was going to run a large VDI (virtual desktop) deployment in several pods. The first pod was designed with two low-cost FC SANs, each having 48 SATA disks. A single SAN should deliver full-clone desktops for 500 users. Running on a “conventional” FC-SAN (no ZFS filesystem or large caches) 48 SATA disks for 500 vDesktops alone is what I’d call a challenge already!
Apart from that they started out right, by choosing a RAID10 configuration. They reserved two SATA disks to function as a hot-spare. So far so good. But then what? You have 46 disks left, and you must put them in a RAID10. They decided so create ONE single RAID10 volume, consisting of 46 disks, thinking that for each I/O performed all disks would be used, boosting performance. On top of that, they decided to use 512KByte as a segment size, because VMware uses a blocksize of at least 1Mbyte anyway (both not true of course). The setup on a disk-level looks something like this:
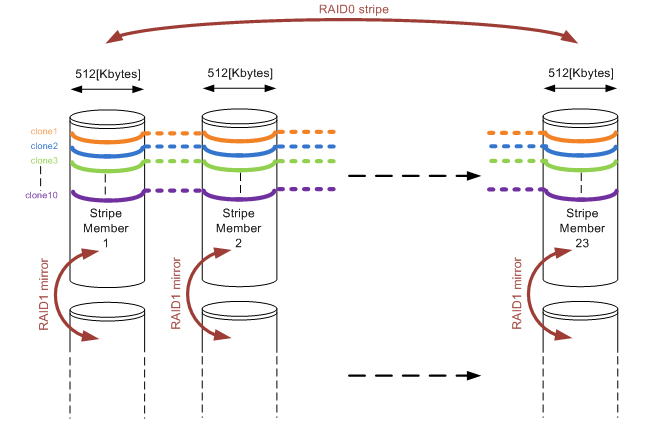
Figure1: RAID10 array consisting of 23 stripe members and showing 10 full-cloned vDesktops layed out on the disks.
For those of you who have read the other parts of my throughput blogs, might already have spotted where things go wrong. In fact things went horribly wrong as I’ll demonstrate in the following section.
What’s happening here?
As described in Throughput part 1: the basics and Throughput part2: RAID types and segment sizes, in a random I/O environment you optimally want only one member of a stripe to perform a seek over a single I/O. That is covered when using 512KB segments. During a complete random I/O pattern, things really aren’t that bad: the randomness makes sure all mirror pairs will be active, no matter how big the segment size might be. The large number of members does not impact rebuild times as well in a RAID10 configuration.
The very large amount of stripe members (23 mirror pairs) in combination with the rather large segment sizes is what really caused the fall though. As soon as the environment was running a larger number of vDesktops, and new vDesktops were cloned, things got bad fast. Full cloning technology was used, which means that each vDesktop has a full image on disk (about 16Gbytes in size). The VDI solution used, was only able to limit the deployment of vDesktops to a number per ESX host. To make a short story even shorter, during a deployment they ran 10 full-cloning actions in parallel against a single SAN. Watch and be amazed what happened!
A day at the races
So why is this blog called “a day at the races” anyway? Well, it simply reminded me of horse racing (and Queen rocks 😉 ). Time for some theory before we prove it also applies in real life. Let’s assume we already have vDesktops already running (let’s say about 250 of them; the number is not really relevant here). They perform random I/O’s on the SAN, loading all disks to some degree (performance wise).
Now we start a single cloning thread (the VDI broker calls for a cloning action to VMware). Sequential reads and writes start to occur (from the template into the new vDesktop virtual disks). Assuming this clone runs at just about 60[MB/sec] (which is a realistic yet theoretical number), and the segment size is 0,5Mbytes over 23 stripe members, each stripe member is accessed about 60 / 0,5 = 120 times every second. No bells ringing yet…
Now think about not one clone, but 10 of these full cloning actions running simultaneously. Remember each cloning action accesses only one stripe member at a time (as they progress through all of the stripe members over and over again). Basically all cloning actions race each other over the stripe members, each a few full-stripes below the other (see figure 1). Assuming they never run at exactly the same speed, it is to be expected two full clones will meet on the same stripe member, slowing things down for these two full clone actions, sticking them to that single stripe member for the time.
As soon as they slow down, the other cloning actions which still run faster “crash” into the rear of this stripe member as well. In the end, all full cloning actions are hammering on the same stripe member, while all other disks are not being accessed by the cloning action at all. Hopefully you’l get the idea when looking at figure 2:
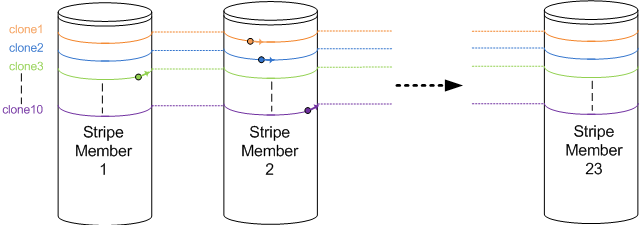
Figure 2: Ten cloning actions racing each other. All are writing on the impacted Stripe Member 2. Clone10 (purple) is about to escape, while clone3 (green) is about to crash into the rear of the impacted Stripe member again.
Each cloning action runs along one of the coloured lines, visiting all stripe members over and over again. Multiple writes being performed to a single stripe member will cause all those writes to slow down (the stripe member gets busier). This in turn causes the other sequential writes which did not slow down yet to “crash into the rear” of the impacted stripe member, causing an even bigger impact. This finally results in all cloning actions hammering on the same single stripe member, forcing the entire SAN to its knees.
As soon as one full clone “escapes the group”, it finds the other stripe members which do not suffer from the hammering. So they pick up speed, race through the non-impacted stripe members, and simply crash into the rear of the stripe member where they just managed to escape from again. Basically, the system will keep hammering on a single stripe member!
In the end, the 10 parallel full cloning actions effectively use one single stripe member, giving the performance of one single SATA disk (RAID 1 write penalty is 2, meaning a stripe member (=mirror pair of disks) perform like a single SATA disk for writes). The overall cloning performance was measured, and went down to about 5 [MB/sec] effectively. Running vDesktops came to a near-freeze.
When you calculate the frequency in which the stripe members are “visited” now, you’ll find that each stripe member is accessed about 5 / 0,5 = 10 times every second. This is a frequency of 10[Hz], very visible to the human eye! So you could actually see this happening on the array (10 times a second the disk activity leds will swipe across the array). Too bad I don’t have a video on that one 🙁
Here some latency graphs on the array during the parallel deployment of 10 full clones:
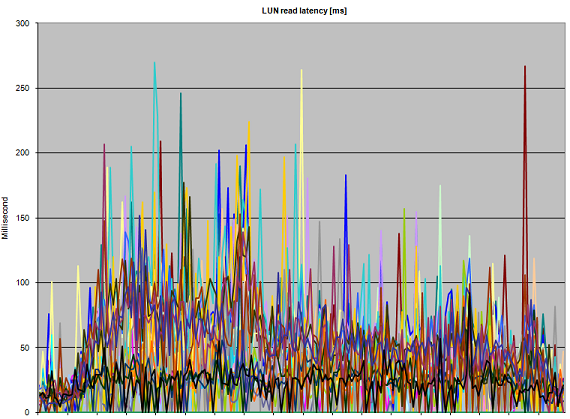
Figure 3: Abnormal read Latency during 10 parallel full-clone actions
Figure 3 clearly shows that performance suffers. Even though the heavy writes are are thought to be the guilty ones, all reads that have to be performed on the impacted stripe member suffer as well, kicking up read latency well over 150 [ms]. The reason the graph keeps touching the lower parts of the graph (which are low-latency reads) are probably the effect of read cache (when disks are not required to service a read request).

Figure 4: Abnormal write Latency during 10 parallel full-clone actions
Write latency in figure 4 is really showing the infamous “A bridge too far”. Especially in the left side of the graph, latencies run up dramatically. The LUNs that draw a thin line along the 10[ms] boundary do not appear to be impacted as much as the other LUNs; this is probably due to the fact that these LUNs are not being written to by a full clone action, so therefore only the random writes performed by the already running vDesktops are registered there. Nonetheless they also see the impact of the cloning (note the starting situation where all write latencies are well below 3 [ms] ).
All other vDesktops running are still performing their random I/O. As long as they do not hit the “impacted stripe member” they just go about their business. But as soon as they hit that stripe member (and they will), they start crawling. In effect, the entire SAN performance appears to crumble, and the vDesktops freeze almost completely.
How to fix things
So how do you fix these issues? The answer is relatively simple: The customer upgraded their disks to 15K SAS drives (being a more realistic configuration for running 500 vDesktops), and they divided the available disks in 4 separate RAID10 groups instead of just one. Also, they decreased the segment size to 64KBytes, which appears a much more sane design.
The smaller segment size will cause cloning actions to stick to a particular segment for a much shorter period of time. More disk volumes with smaller number of members in the stripe will help to isolate performance impact. Together with faster disks performance was boosted effectively (a 15K SAS drive delivers about three times the amount of IOPS a single 7K2 SATA disk can handle).
Throughput part 3: Data alignment
A lot of people have discovered yet another excuse why their environment is not quite performing as it should: misalignment. Ever since a VMware document stated misalignment could potentially cost you up to 60% of performance, it has become an excuse. When looking closer, the impact is often nearly negligible, but sometimes substantial. Why is this?
Introduction
It is more and more seen in VMware environments today. “You should have aligned the partition. No wonder performance is bad”. But what is misalignment exactly, and is it really that devastating in a normal environment? The basic understanding of misalignment is rather simple. In RAID arrays, there is a certain segment size (see Throughput part 2: RAID types and segment sizes). This means data is striped across all members of a raid volume (a set of disks strung together to perform as one big unity). Especially when performing random I/O (and most VMware environments do), you want only a single disk to have to perform a track seek in order to get a block of data. So if your segment size on disk is 64KB, and you read a block of 64KB, only one disk has to seek for the data. That is, IF you aligned your data. If somewhere in between the data is not aligned with the segments on disk, you’d possibly have to read two segments, because each segment carries part of the block to be read (or written for that matter). Exactly that is called misalignment.
In most VMware environments, there are two “layers” between your VM data and the segments on disk: the VMFS and the file system inside your virtual disk. Since ESX 3.x, VMware delivers 64KB alignment of the VMFS. As soon as the blocks vSphere is accessing get bigger than 64KB, you could call it sequential access, where alignment does not help anymore. So basically the start of a VMFS block of 64KB, is always aligned to a 64KB segment on the disks laying underneath. For those who might wonder: VMFS block sizes (1MB … 8MB) are not related to the I/O sizes used on disk; VMFS is able to perform I/O on subsets of these blocks.
The second “layer” is more problematic: The guest file system. Especially NTFS under Windows 2003 server (or earlier) or desktop releases prior to Windows 7, NTFS will by default misalign. I have never understood why, but a default NTFS will align itself to 32256 bytes, or 63 sectors. After that the actual data starts. Getting NTFS aligned is simple: just create a gap after sector 63 right up to sector 128 (or any power of two above for that matter). This is easily done for new virtual disks, but not so easy for existing ones (especially system disks).
Misalignment shown graphically
A lot of people find misalignment hard to understand. A picture says a thousand words, so in order to keep this blog post somewhat shorter: pictures!

In figure 1, both VMFS and NTFS have been properly aligned, including some alignment space. In effect, for every block accessed from or to the NTFS file system, only one block on the underlying storage is touched. Thumbs up!

A misalignment of both VMFS and NTFS is depicted in figure 2. This is a really undesirable situation. As you can see, the access of an NTFS block will require one VMFS segment to be read, sometimes even two (due to NTFS misalignment). But since VMFS is misaligned to the disk segments, every 64KB VMFS block in this example will require the access to two segments on disk. This can and will hurt performance. Luckily, VMware spotted this problem relatively early, and from ESX 3.0 and up VMFS alignment is automagically if you format the VMFS from the VI client.

Figure 3 shows the situation I mostly see in the field. VMFS is aligned (because VMFSses formatted in the VI client align automagically to a 64KB boundary). NTFS is misaligned in this example. I see this all the time in Windows 2003 / Windows XP VMs. As you can see in this example, most blocks touch only a single segment on the physical disk. Some NTFS blocks “fall over the edge” of a 64K segment on disk. Any action performed on those NTFS blocks will result in the reading or writing of TWO segments on the underlying disks. This is the performance impact right there.
You can probably see where this is going: If your segment size on your storage is way bigger than the block size of your VM file system, impact is not too much of a problem. In the example in figure 2, two NTFS blocks out of every 64 blocks will be impacted by this, and only for random access (in sequential accesses your storage cache will fix your problem since both segments on disk will be read anyway). This is an impact of 1/32th, or 3,1%. You could possibly live with that…
Now let’s up the stakes. What if your storage array used a really small segment size on physical disk, let’s say 4KB? Take a look at figure 4:

vSphere will generate I/O blocks which get sized to the highest effectiveness. For example, if you have a database which uses 4KB blocks, and performs 100% random I/O, you get a situation like in figure 4. Every time you access a 4KB block, VMFS interprets this to a 4KB I/O action to your array. Because the NTFS / database blocks are misaligned, EACH access to a 4K block ends up on TWO disk segments. This impacts performance dramatically (up to 50% if all I/O sizes are 4KB). A similar situation occurs when your database application would use 8KB blocks; in that case for every I/O three segments on disk would be accessed instead of two, impacting performance of the disk set by 33% (if all I/O sizes are 8KB).
Why ever use a small segment size?
When you look at an EMC SAN (Clariion), the segment size is fixed at 64KB . When you look at a NetApp, segment size is fixed at 4KB. It would be pretty safe to say, that the impact of misalignment will hit harder on a NetApp than on an EMC box. That is probably why NetApp hammers so hard on alignment; in a NetApp environment it really does matter, in an EMC environment, a little less.
Looking at it the other way round: Why would you ever use such a small segment size? Why not use a segment size of for example 256KB, and feast on having only 1/128th or 0,78% impact when not aligning? Well, using a large segment size appears to be the solution to misalignment. And in a way, it is. But do not forget: Every time you need to access 4KB of data, 256KB is accessed on disk. So both yes AND no, a large segment size makes alignment almost a waste of time, but it introduces other problems.
Somewhere, the “perfect segmentsize” should exist. Best of both worlds… The problem is… This perfect segment size will vary with the type of load you feed to your SAN. EMC is sure about their 64KB (since it cannot be altered), NetApp seems sure about 4KB, because of the very same reason. The el-cheapo parallel-SCSI array (yes parallel SCSI indeed and vmotion works- but that is another story) I use for my home lab does a more generic job: For each RAID volume, I am allowed to choose my segment size (called a stripe size there). Now THAT gives room for tuning! And room for failure in tuning it at the same time…
Dedup and misalignment
Now that deduplication is the new hype, misalignment is said to impact dedup effectiveness. The answer to this, as usual, is…. It depends. If you take two misaligned windows 2003 servers from a template, you’d deduplicate them very effectively since they are very alike. If you were to align one of them (leaving the second one misaligned), dedup would possibly not find a single block in common. Makes sense right? Your alignment shifted all data within the VMDK, differentiating all blocks in effect. If I now align the second VM as well (using the same alignment boundary), dedup would once again be able to work effectively.
So the final answer should be: If dedup is to be effective, either align ALL VMs, or align NONE.
How to get rid of misalignment
Let’s say you’ve found that your VMs are misaligned. If things are really bad they are situated on a RAID volume with a very small segment size. Alignment could save the day. So how do you go about it? Several solutions I’ve come across:
- Manually;
- GParted utility;
- Use Vizioncore’s vOptimizer;
- If you’re a NetApp customer and use ESX (not ESXi), use their alignment tool mbrscan/mbralign;
- V2V your VMs using Platespin PowerConvert and align them on the way.
Manual Alignment is perfect for data drives. The idea is that you add a second data drive, create an aligned partition there using diskpart:
- Open a command promp, run diskpart;
- list disk – then select disk x;
- list volume – then select volume x;
- create partition primary align=64 (or any power of 2 above).
after that, stop whatever service is using your datadrive, copy all data, change the drive letters so your new aligned disk matches the old data drive, restart your services, remove the original data disk from the VM. This works great for SQL, Exchange, fileservers etc. The big downside: You cannot align system disks using diskpart (not even from another VM; diskpart’s create partition is destructive).
GParted is a utility that is said to align your partition if you resize the partition using this tool. Never looked into it, but it’s worth checking it out.
Vizioncore’s vOptimizer is a very nice tool that performs alignment for you. Basically it shuts the VM in question, and starts to move every block inside your VMDK(s). You end up with all disks aligned. The VM is then restarted and an NTFS disk check is forced. After that you’re good to go. It served me well on some occasions! You even get two alignments for free if you decide to give their product a spin.
NetApp customers get an alignment tool for free: mbralign. I never used this tool, but apparently it does about the same job as vOptimzer. It shuts your VM, aligns the disks, reboots your VM. It only works on ESX though (installs software in the Service Console).
If you cannot live with the downtime, but need to align anyway, you could consider to look at Platespin products. They can perform a “hot” V2V and align in the process. When data moving is complete, they fail over from the original VM to the newly V2Ved VM, syncing the final changes on the destination disk(s). You end up with an aligned copy of your VM with minimal downtime.
How to prevent misalignment in the first place
Misalignment is often seen, but not necessary at all if you think about it before you start: A lot of people create templates. Not too many align their templates… But you could! If you have a (misaligned or not) VM laying around, you could add an empty system disk of the template-to-be to it, and format the partition aligned from that “helper” VM (see the diskpart description above). Then detach the system disk from the helper VM again, and proceed to install Windows on the (now aligned) disk. Choose not to change anything to the partitioning and you are good to go. Bootable XP CD’s can also do the same trick here.
Now your template is aligned. The upshot: Any VM deployed from this template is too!
There is an easy way to check under windows if your disks are aligned. Simply run the msinfo32.exe from windows, expand components, storage, disks. Find the item “Partition Starting Offset”. If it reads 32.256, you’re out of luck: your partition is misaligned. If it reads 65536, you have a 64K aligned partition. If the value reads 1.048.576, the partition is aligned on a 1MB boundary (Windows 2008 / Windows 7 default).
Conclusion
Is alignment important? Well, it depends. It particularly depends on the segment size used within your storage array. The smaller the segment size, the more impact you have. Bottom line though: Alignment always helps! Get off to a good start and perform alignment right from the beginning and you’ll profit ever after. If you didn’t go off to a perfect start, consider aligning your VMs afterwards. Start with the heavy random I/O data disks for sure, but I would recommend to have the system disks aligned as well, using one of the described tools.
Throughput part 2: RAID types and segment sizes
In part one I covered all stuff you can think of in regards to delays and latencies you encounter on physical disk drives and solid states. Now it is time to see how we can string together multiple drives in order to get the performance and storage space we actually require. I’ll discuss RAID types, number of disks in such a RAID set, segment sizes to optimize your storage for particular needs and so on.
–> For those of you who haven’t read part 1 yet: Thoughput Part1: The Basics
A short intro to RAID types
Now finally it is on to the stringing together of disks. More disks is more space, more performance, right? Yes right – sometimes. I am not zooming in too deep on the RAID types. I assume you have some knowledge on different types of RAID, mainly RAID1, RAID10 and RAID5. All that I’ll say about it: Read the rest of this entry »
Breaking VMware Views sound barrier with Sun Open Storage (part 1)
A hugely underestimated requirement in larger VDI environments is disk IOPs. A lot of the larger VDI implementations have failed using SATA spindles, when you use 15K SAS or FC disks you get away with it most of the times (as long as you do not scale up too much). I have been looking at ways to get more done using less (especially in current times, who doesn’t!). Dataman, the dutch company I work for (www.dataman.nl) teamed up with Sun Netherlands and their testing facility in Linlithgow, Scotland for testing. I got the honours of performing the tests, and I almost literally broke the sound barrier using Suns newest line of Unified Storage: The 7000 series. Why can you break the sound barrier with this type of storage? Watch the story unroll! For now part one… The intro.
What VMware View offers… And needs
Before a performance test even came to mind, I started to figure what VMware View offers, and what it needs. It is obvious: View gives you linked cloning technology. This means, that only a few full clones (called replicas) are read by a lot of Virtual Desktops (or vDesktops as I will call them from now on) in parallel. So what would really help pushing the limits of your storage? Exactly, a very large cache or solid-state disks. Read the rest of this entry »


 LinkedIn
LinkedIn Twitter
Twitter